New – Accelerate SAP Deployments with AWS Launch Wizard
Today, I am excited to announce AWS Launch Wizard for SAP, a new service that is speedy, easy, flexible, secure, and cost effective for customers. This new service helps Customers to deploy SAP applications on AWS by orchestrating provision of underlying AWS resources using AWS CloudFormation and AWS Systems Manager.
Thousands of AWS customers have built and migrated their SAP workloads using AWS Quick Start and Amazon Elastic Compute Cloud (EC2), including x1, x1e, and high memory instances. In addition, they also take advantage of the AWS Partner Network (APN) for SAP to find solutions that work for them. SAP Customers want well architected intuitive wizard to deploy SAP system with best use of AWS resources.
AWS Launch Wizard for SAP is designed for customers who want to deploy new SAP workloads on AWS or migrate existing on-premises SAP workloads to AWS with the following benefits:
- Deployment efficiency: AWS Launch Wizard for SAP recommends the Amazon EC2 instances that fit your SAP workload requirements and automates the launch of AWS services for SAP systems with recommended configurations and minimum manual input. Launch Wizard helps customers achieve faster time to value for provisioning and accelerates deployment of SAP applications by 2X. Being able to quickly launch SAP environments improves the customer’s agility to support new business initiatives.
- Prescriptive guidance: AWS Launch Wizard for SAP guides customers with correct sizing and provisioning of AWS services for SAP systems based on best practices from thousands of SAP on AWS deployments.
- Faster learning curve: AWS Launch Wizard for SAP offers an SAP-oriented user experience for customers. It provides guided deployment steps aligned with SAP deployment patterns and uses SAP terminology which creates a familiar experience for SAP users.
AWS Launch Wizard for SAP – Getting Started
To get started with an SAP deployment, in the Launch Wizard console, you can click the Create deployment button and select the SAP application.

When you click on the Next button, you can provide Deployment Name and Infrastructure settings. Infrastructure settings can be saved based on how you want to classify your deployment using the infrastructure. They can be reused for SAP systems deployments that share the same infra configuration.
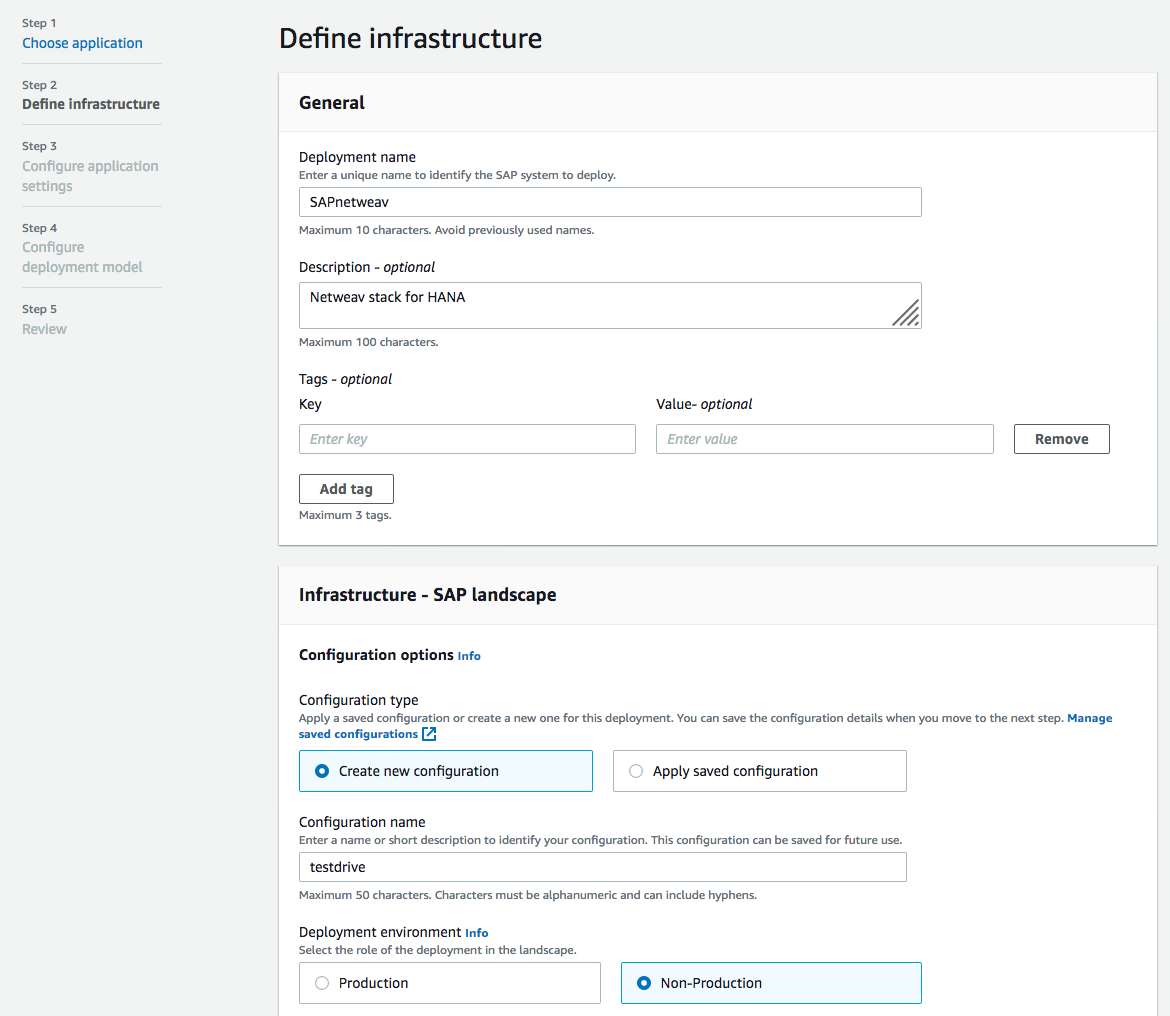
Assign a key pair and select the VPC which to deploy the SAP instances. After you select the Availability Zones and private subnets, you can assign security groups to the EC2 instances that will run the SAP applications.

After setting SAP System Admin IDs, you can set the topic of Amazon Simple Notification Service (SNS) to get alerts about SAP deployments. By clicking the Next button, we can go to the application settings.

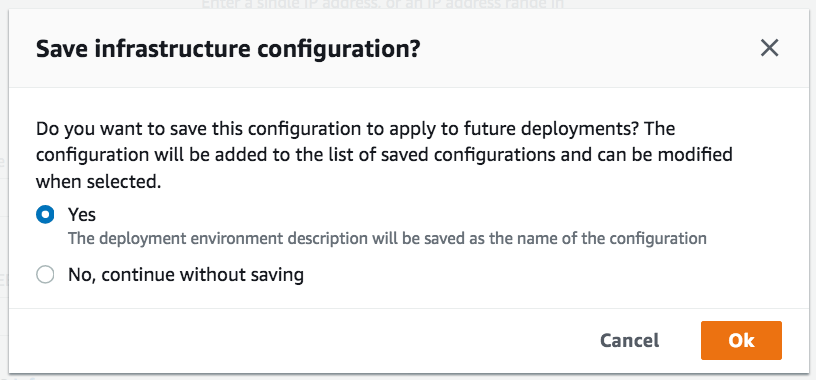
If you save infrastructure configurations, you can reuse to apply to future deployments.
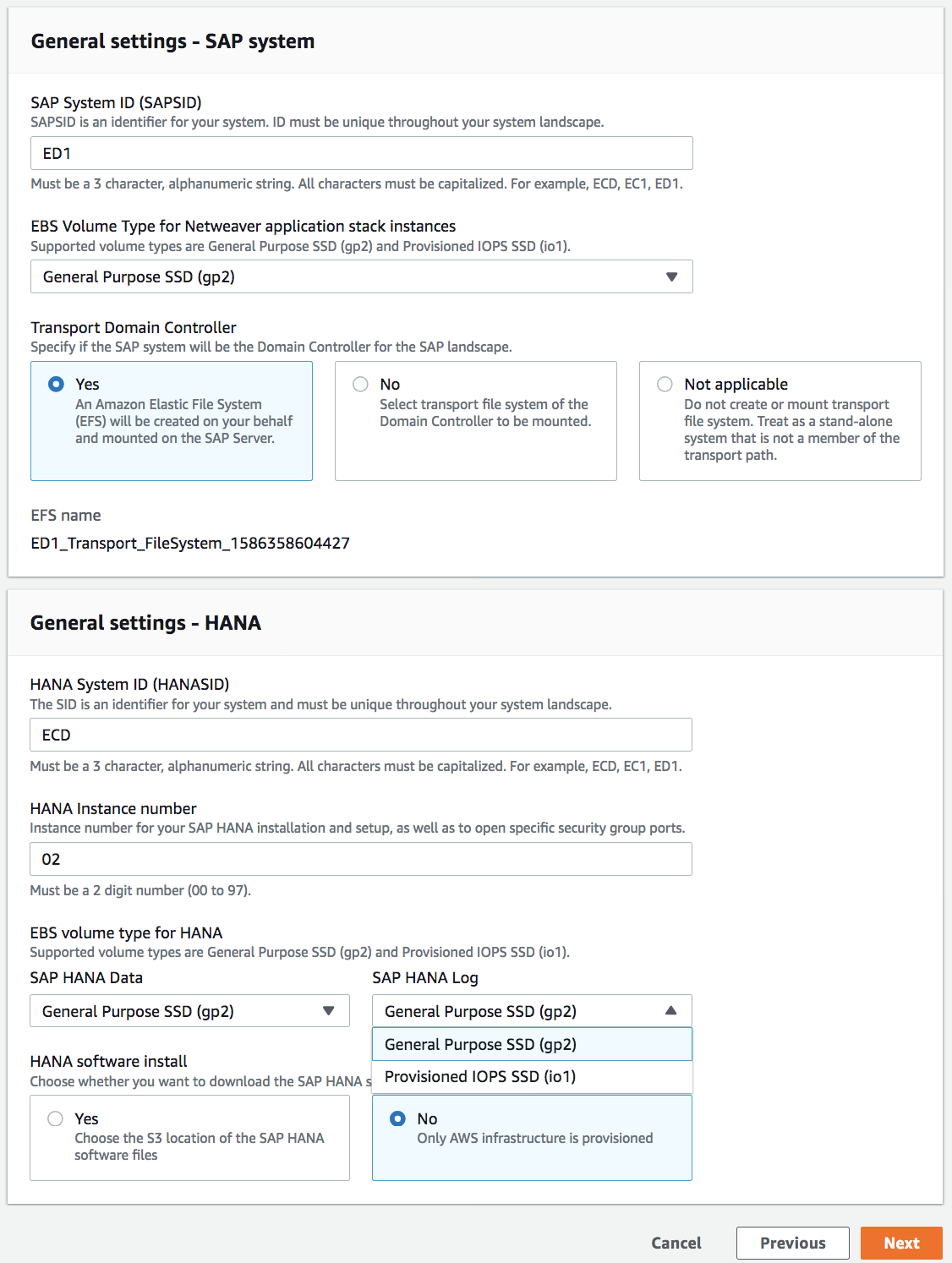
Configuring application settings, AWS Launch Wizard for SAP supports two types of SAP applications: NetWeaver stack on SAP HANA database deployments and HANA database deployments.

You can provide SAPSID, HANASID, and the instance number used in the SAP HANA installation and then configure the AWS resources based on these inputs. It supports two EBS volume types for SAP HANA Data and Log: HANA data and log – General Purpose SSD (gp2) and Provisioned IOPS SSD (io1). Optionally, a customer can choose to provide HANA software hosted on an S3 bucket to deploy HANA configured for high availability using SLES/RHE.
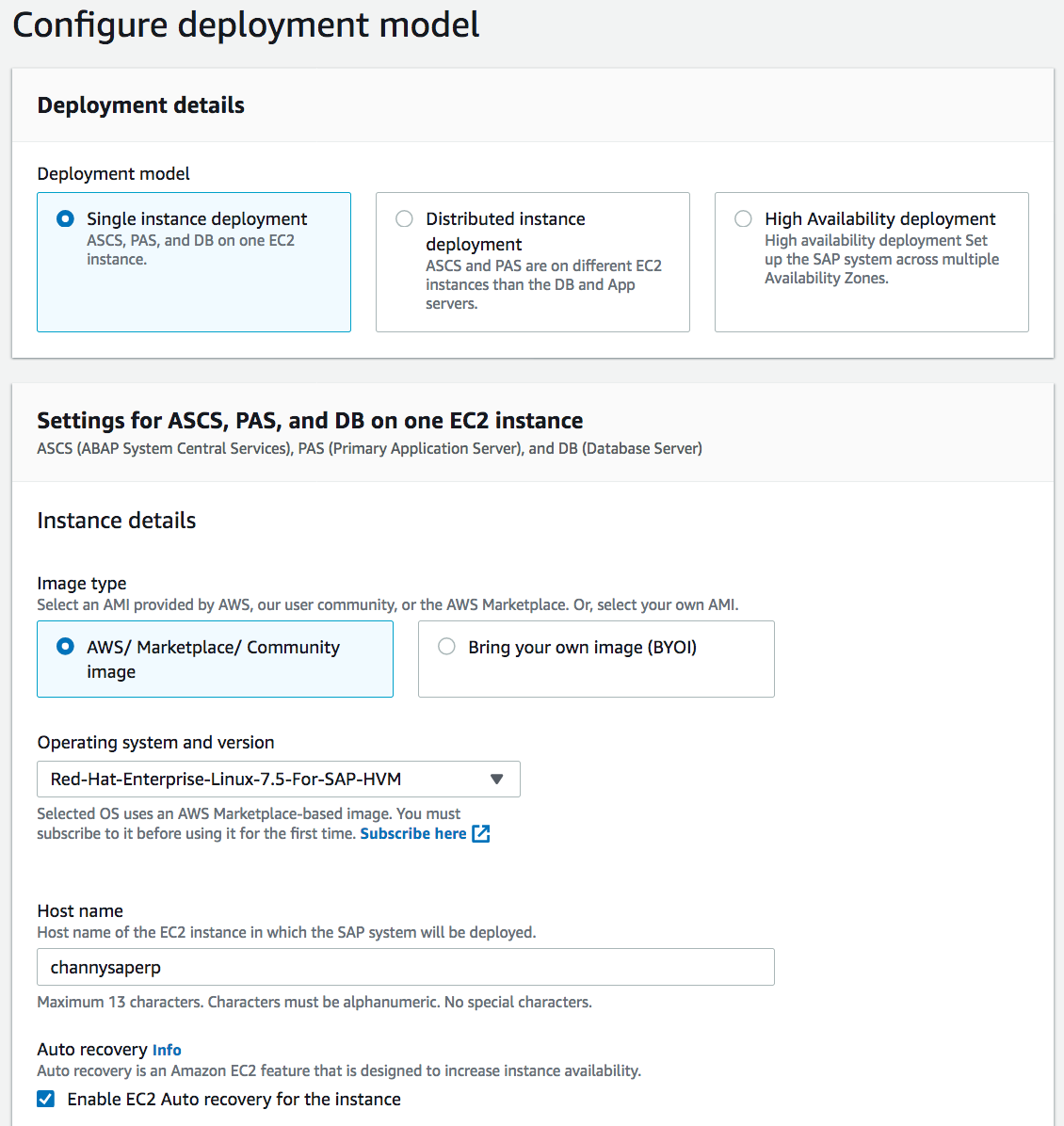
Next, you can configure the deployment model with SAP supported Operating Systems such as SUSE Linux and RedHat Enterprise within a single instance, distributed instances , and high availability patterns in multi AZs.
When you define the infrastructure requirement, you can use the recommended guide to provide vCPU/Memory or manually choose the instances from the list of SAP supported EC2 instances for the SAP component (ASCS or ERS or APP or HANA DB) and then deploy the SAP components on it. You will be able to see the cost estimates for the AWS resources – Amazon EC2, EBS, and EFS volumes – that will be provisioned for a particular deployment.
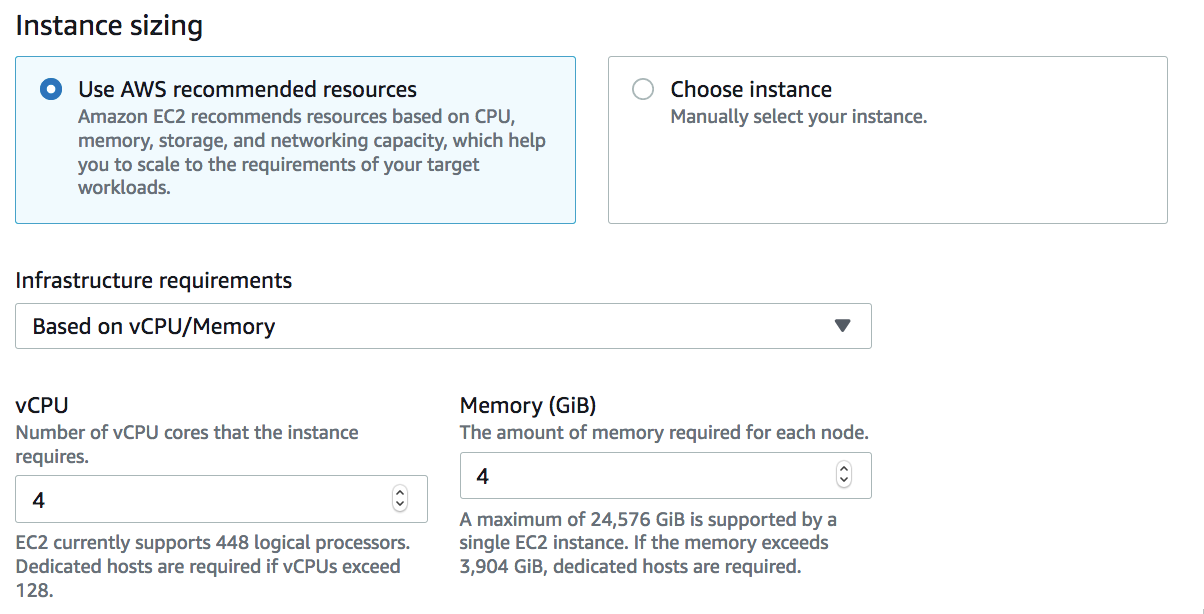
After reviewing all your configurations, you can simply deploy by clicking Deploy button.
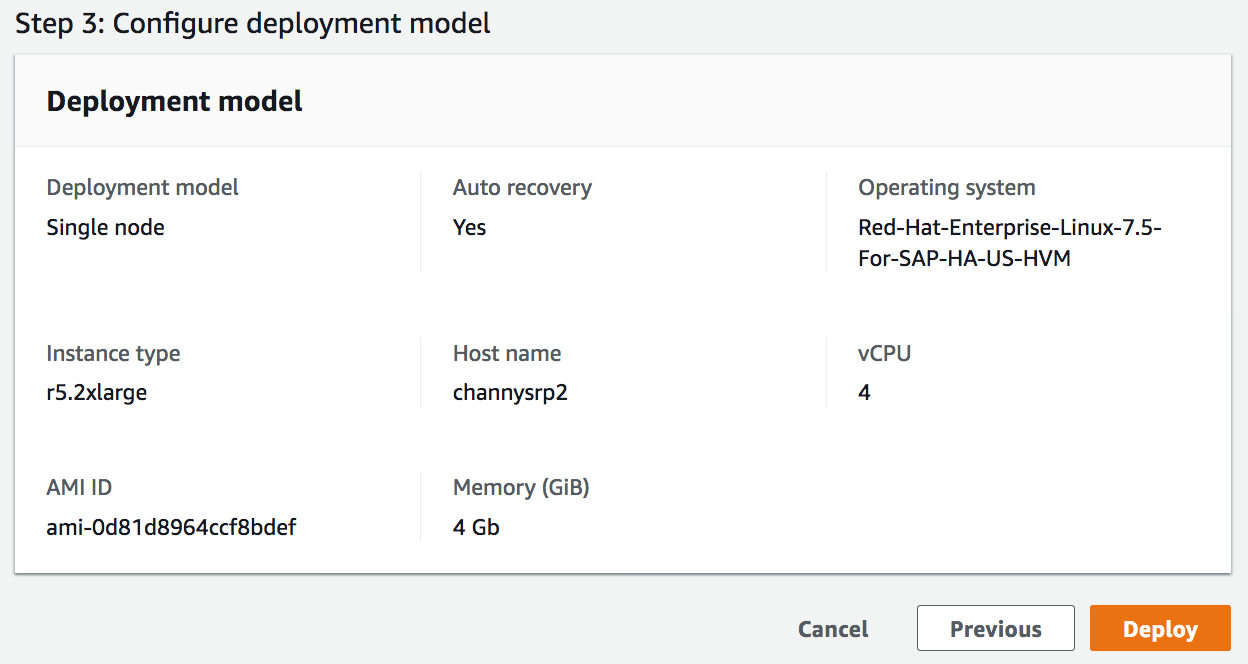
Depending on the chosen deployment it takes 1 to 3 hours. You will be able to see which SAP systems have been deployed, what infrastructure configuration was used for the deployment, what components of SAP were deployed, and a mapping of SAP components to EC2 instances.
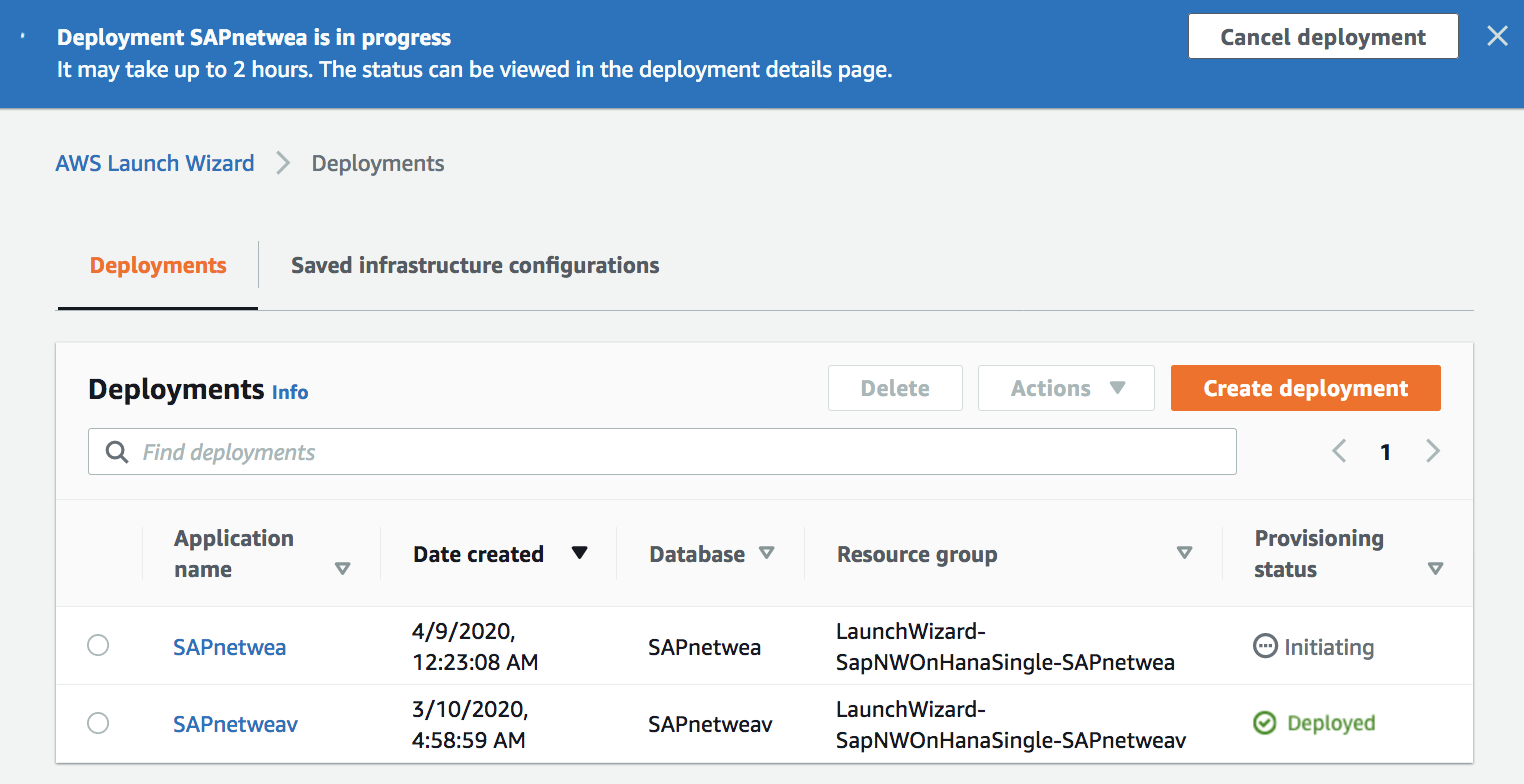
Now Available!
AWS Launch Wizard for SAP is generally available and you can use it in US East (N. Virginia), US West (Oregon), Europe (Ireland), US West (N. California), US East (Ohio), Europe (Ireland), Europe (Paris), Europe (Frankfurt), Asia Pacific (Tokyo), Asia Pacific (Seoul), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Mumbai), South America (São Paulo), Europe (London), Canada (Central), Europe (Stockholm). There is no additional charge for using AWS Launch Wizard, only for the resources it creates. Take a look at the product page and the documentation to learn more. Please send feedback to SAP Contact Us, AWS SAP partners or through your usual AWS support contacts.
AWS Launch Wizard for SAP is generally available and you can use it in US East (N. Virginia), US West (Oregon), Europe (Ireland), US West (N. California), US East (Ohio), Europe (Ireland), Europe (Paris), Europe (Frankfurt), Asia Pacific (Tokyo), Asia Pacific (Seoul), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Mumbai), South America (São Paulo), Europe (London), Canada (Central), Europe (Stockholm). There is no additional charge for using AWS Launch Wizard, only for the resources it creates. Take a look at the product page and the documentation to learn more. Please send feedback to SAP Contact Us, AWS SAP partners or through your usual AWS support contacts.
— Channy;





 showing training points distributed on each fold at the end of the time period to eliminate data leakage during validation")








